As other Generative Models, diffusion models aim to learn the data distribution in order to sample new points from it, hence generating new pieces of data. The idea was introduced in the paper by [@sohl-dicksteinDeepUnsupervisedLearning2015], and then improved in the following papers:
- [@hoDenoisingDiffusionProbabilistic2020]
- [@nicholImprovedDenoisingDiffusion2021] by OpenAI
- [@dhariwalDiffusionModelsBeat2021] by OpenAI
Diffusion model’s way of generating new data samples is, starting from a certain point, gradually add Gaussian noise, and then reversing the process.
The multiple tiny steps are a Markov Chain, and because they are small they are also easy to analyze.
Forward Process
In the forward process, the model starts from a point and gradually adds some Gaussian noise to it, which amount is controlled by the noise schedule , which can be different at each timestep . The process is repeated for steps.
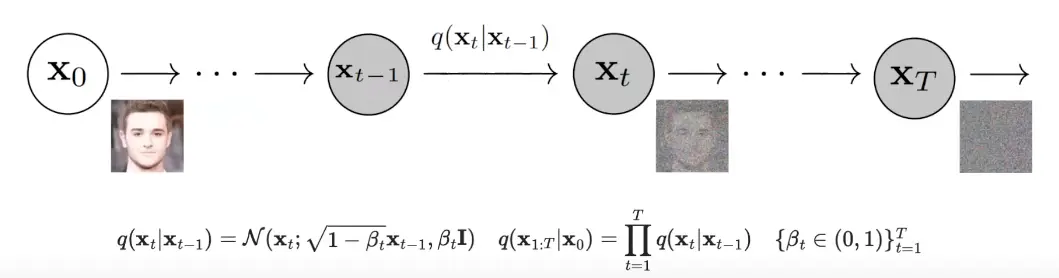 If approaches infinity, the result will be pure random noise (Isotropic Gaussian).
If approaches infinity, the result will be pure random noise (Isotropic Gaussian).
The function that models the forward process is defined as:
On the noising schedule
In the paper by [@hoDenoisingDiffusionProbabilistic2020], the authors used a linear noising schedule.
On the other hand, in the OpenAI paper by [@nicholImprovedDenoisingDiffusion2021], they improved the model by using a cosine noising schedule, since the linear schedule had the problem that in the early steps data was destroyed too fast, and the last steps were redundant.
Reverse Process
In the reverse process, the model aims to learn the denoising process to undo each step of the forward process.
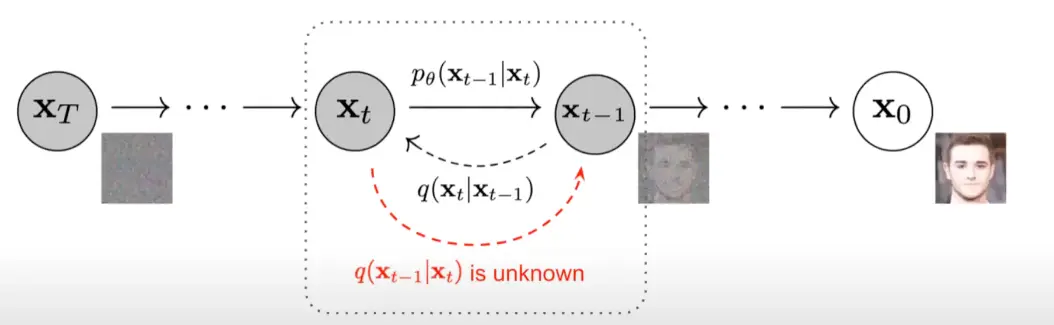 Once learned, we can take a random noise data point, apply the denoising process, and at the end we will obtain a new generated data point from the learned distribution.
Once learned, we can take a random noise data point, apply the denoising process, and at the end we will obtain a new generated data point from the learned distribution.
Finding the exact distribution for each time step is hard, since it depends on the entire data distribution, hence the problem is computationally intractable.
It turns out that for small enough forward septs, the revers process step can be estimated as a Gaussian distribution too (just to know, the reason of this assumption lies in the nature of stochastic differential equations), hence we can parametrize the learned reverse process as a gaussian:
such that:
In order to learn, we need a loss function.
tags: deep-learning resources: CS 198-126: Lecture 12 - Diffusion Models - YouTube