Retrieval-Augmented Generation is a framework that allows Large Language Models to be more accurate and more up-to-date with the information.
The generation part refers to the LLMs that generate texts in response to a prompt (user query).
The problem in the interaction with LLMs models is the fact that they cannot cite the source where they took the information, and that information can be out-of-date. If the model could source the source where it took the information, and it can update itself when new up-to-date information is fed to it, those problems are solved.
If we add some content store (which can be open like the Internet, or closed like a predefined set of documents), then the LLM can query that content store before answering the question (question that is now Retrieval-Augmented) it can cite the source, and be sure to be up-to-date.
Note that the information from the content store that is the most relevant to the user query is given to the LLM model by a model called the retriever, which accuracy heavily impacts the accuracy of the final response.
The fact that we can update the content store, it’s incredibly useful since we can update the information the LLM need without actually re-training or fine-tuning the LLM, which is an expensive operation.
This makes the model also less likely to hallucinate, since it doesn’t relies sorely on training information.
With this type of framework, the model is also able to say “I don’t know” to a question if the question cannot be answered by looking at the content store.
Pipeline
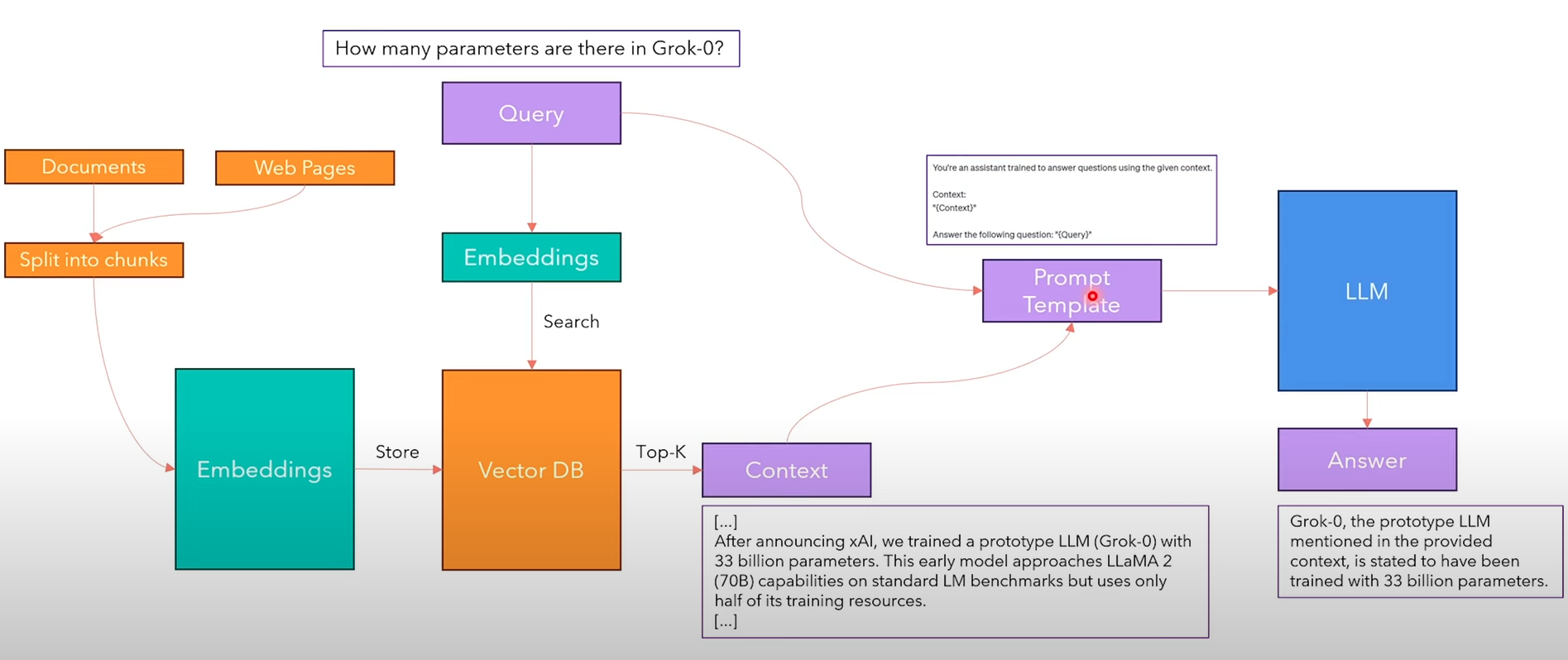
The RAG pipeline is the following:
- We take a corpus of documents and web pages that will be our content store, and we split them into chunks
- Using an embedder model (such as Sentence-BERT), we create embeddings of these chunks and store them into a Vector Databases. Note that each embedding is also paired with the original text, so that later we can map embeddings to the actual embedded text.
- Given the Query to the LLMs, we embed it using the same embedder model used fo the content store.
- We search the top-k embeddings in the vector DB that are most similar to the query embedding. This will be our context.
- Now that we have the Query and Context, we create a Prompt Template (similarly to what happens in Prompt Engineering).
- We feed the prompt to the language model, which will be capable of answering the questions with the provided augmented data.
RAG vs. Fine-Tuning vs. Prompt Engineering
tags: deep-learning nlp sources: