We can use BERT to embed entire sentences by just removing the linear layer and performing mean pooling (i.e. taking the average of all the token embeddings) to get the sentence embedding.
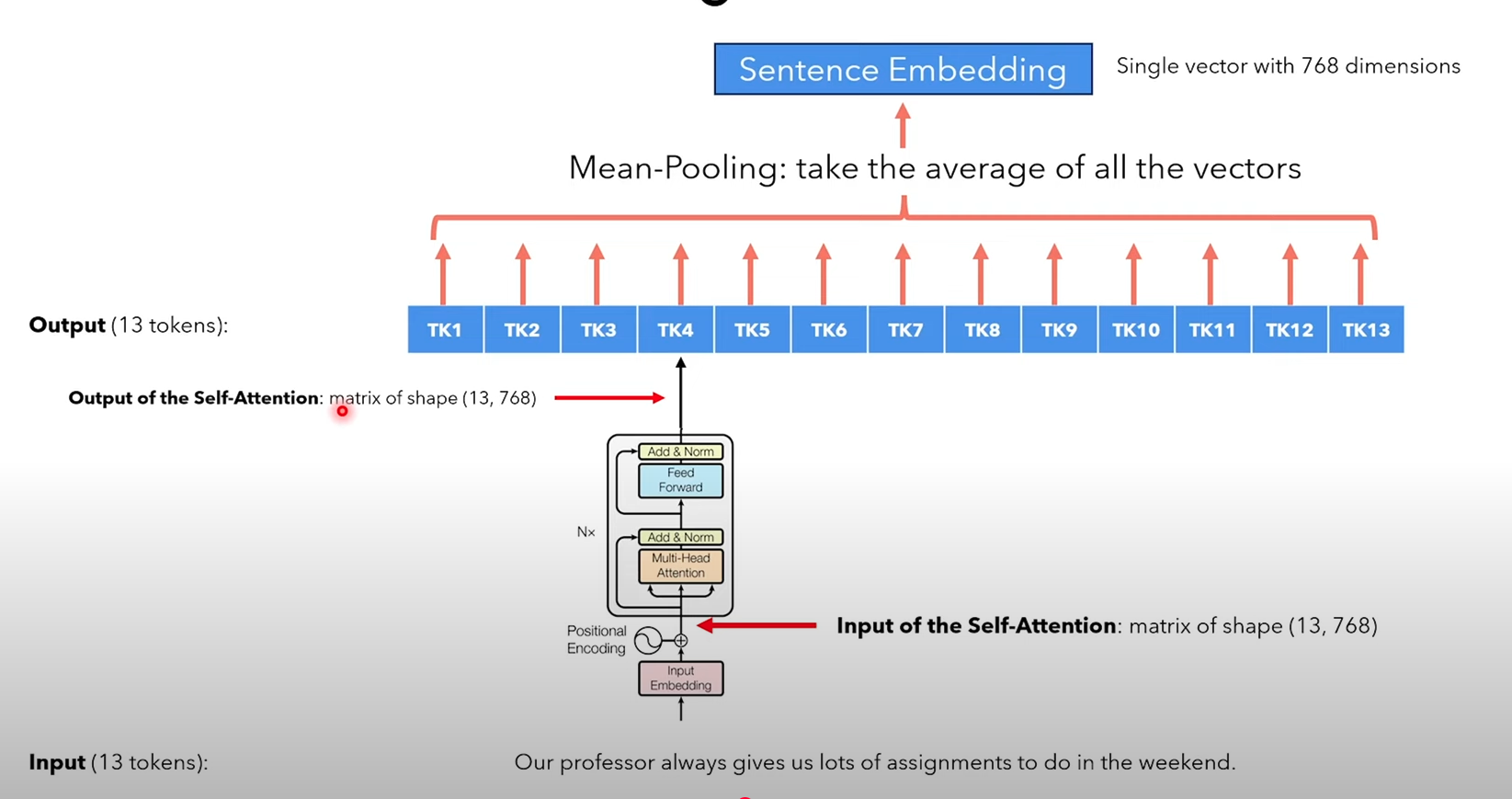
However, since BERT was not trained for sentence similarity, the resulting embeddings might not reflect semantic closeness accurately when using similarity functions.
Sentence-BERT (SBERT), a modified version of BERT, is specifically trained to produce sentence embeddings that are compatible with similarity measures like cosine similarity.