In a multimodal system, fusion is the act of taking the information carried by different modalities, and fusing them together in order for the system to be able to interpret it.
Fusion techniques are mostly applied to complementary and redundant modalities (see cooperation between modalities for more info).
Given the input interpretation diagram (Figure below), fusion can happen at different levels.
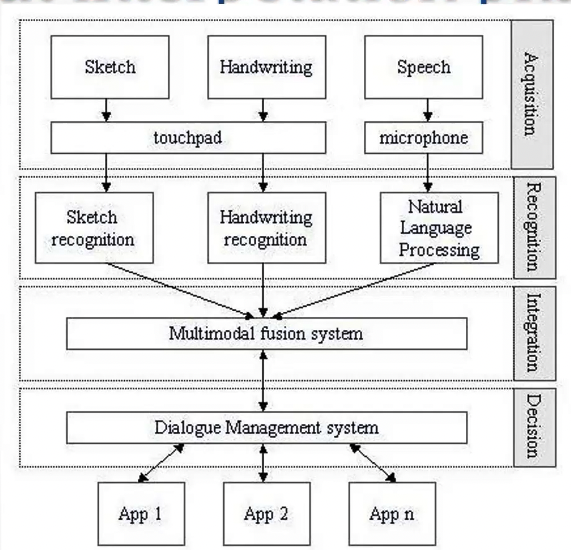
Fusion at the acquisition (or signal) level
This type of fusion is performed immediately after the acquisition level, it consists in fusing two or more signals. This can be done only if the signals are synchronized and of the same nature (we can’t fuse an image signal with an audio signal);
Fusion at the recognition (or feature) level
Also called early fusion, is performed immediately after the recognition level, it consists of merging the embeddings or feature vectors that are outputted by the models. The fused feature vector is then inputted into another model to make the final decision.
In order to perform fusion at recognition we need tome appropriate structures to represent the input signals, such as action frames, input vectors or slots
Action Frames
A multimodal input event can be modeled as a set of parallel streams, each belonging to a modality. Integrating different streams consists in creating parameter slots. The combination of these elements make up an action frame, which specifies the action that has to be performed in response to the multimodal input.
Action frames are introduced in 1998 by Minh Tue Vo1.
(A Framework and Toolkit for the Construction of Multimodal Learning Interfaces, p.47) The user might say “How far is it from here to there?” while drawing an arrow between two points on the displayed map. The speech input stream consists of the words in the utterance whereas the pen input stream contains a pair of
arrow_startandarrow_endtokens. The interpretation of this input combination is aQueryDistanceaction frame containing aQueryDistanceSourceparameter slot followed by aQueryDistanceDestinationparameter slot. The input streams are segmented and aligned as follows:If the destination point is somewhere outside the displayed area, the user might say “How far is it from here to Philadelphia?” and circle the starting point instead. In this case the input segmentation becomes
For the utterance “How far is it from Pittsburgh to Philadelphia?” the parameter slots would consist of speech segments only.
The integration of the information streams is carried out through the training of a Multi-State Mutual Information Network (MS-MIN). #todo better see what is this MS-MIN
Input Vectors
Introduced in 1997 by Pavlovic et al.2, input vectors are used to store the outputs of the visual and auditory interpretation modules.
In the paper, they describe how first the visual module extracts the video features by performing color-based segmentation, followed by motion-based region tracking and then moment-based feature extraction. While the audio module extracts the features by doing pre-emphasis, windowing and then cepstral frequency analysis.
Those features are classified using Hidden Markov Models, specifically, the authors refer to HMM PIN (Probabilistic Independence Networks for Hidden Markov Models).
(Integration of audio-visual information for use in human-computer intelligent interaction, p.122) The observable state space of each HMM is defined as the direct product of the selected feature spaces of the visual and the auditory modules. For instance, if the selected gestural features are gestural words and the selected auditory features are spoken words then the integration module’s state space consists of all possible pairs of gestural and spoken words, in total.
They refer to this type of combination as phoneme and viseme combination.
Slots
Proposed by Andre et al. in 1998,3 the authors were trying to implement a multimodal system with hand gestures and voice commands to manipulate objects and tools in a drawing program.
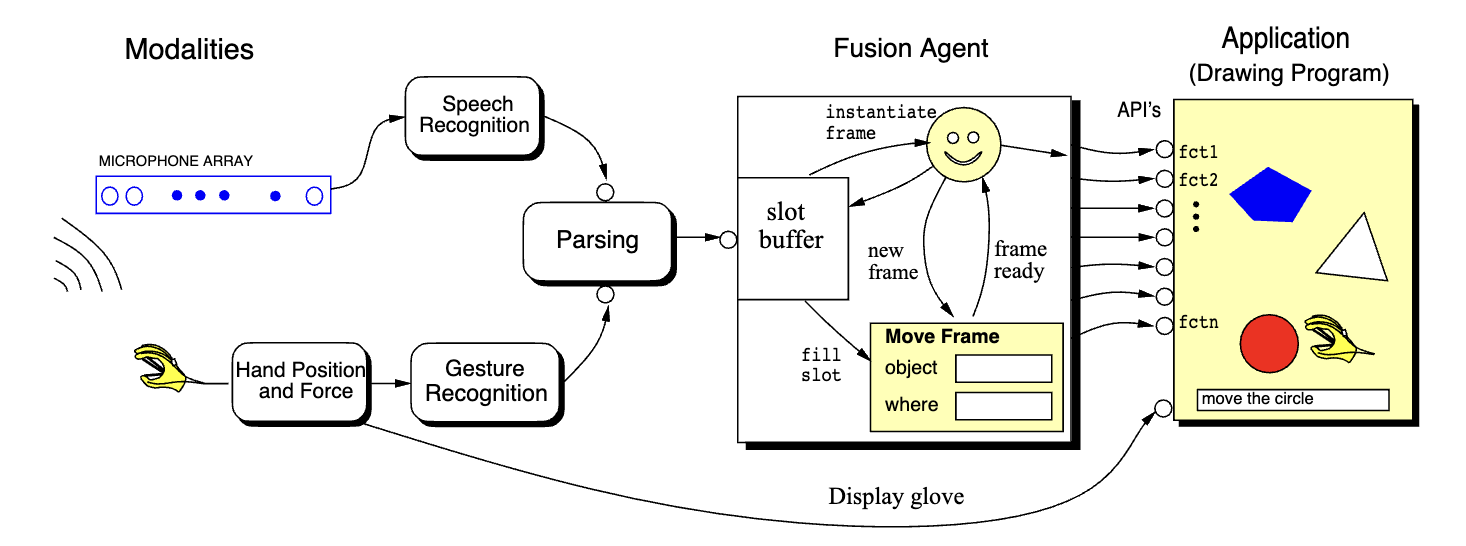 To fuse the information, they use a slot buffer, which elements inside has the ability to reference past lexical units (the word “it” can reference the object that it refers to). Each information is stored in semantic units called frames. All the elements inside of a frame refer to the same semantic, and are called slots. (e.g. considering the “move” frame, we can identify the “object” slot that defines which is the object, and the “where” slot, which define where is the object. The actual information is filled by the multimodal input).
To fuse the information, they use a slot buffer, which elements inside has the ability to reference past lexical units (the word “it” can reference the object that it refers to). Each information is stored in semantic units called frames. All the elements inside of a frame refer to the same semantic, and are called slots. (e.g. considering the “move” frame, we can identify the “object” slot that defines which is the object, and the “where” slot, which define where is the object. The actual information is filled by the multimodal input).
A daemon agent continuously monitors for filled frames, and when this happens the fusion agent sends the filled frame to be executed in the application.
Integration of Speech and Gesture for Multimodal Human-Computer Interaction, p.3 Our approach to multimodal fusion is a variation of the slot-filler approach where a slot-buffer stores the incoming values for all possible slots de fined by the command vocabulary. First, the parser fills the slots that are designated in the utterance and reads the mouse position when appropriate. For example, the utterance. “From here to here create a red rectangle” causes the following slots to be filled in the slot-buffer: the positions of the two opposite corners of the object, the object’s type, the object’s color, and the operation or command type. A demon is watching the slot-buffer to see if the command slot is filled. If it is filled, then it will instantiate the appropriate command frame and examine if there is enough information in the slot-buffer to fill the predefined slots of that particular frame. Then the command will be executed through the application interface. If it is not filled, then the system will wait for more information.
Fusion at the decision (or conceptual) level
Also called late fusion, we run all the models independently and make them output a decision, and we fuse the final decision with a voting mechanism.
This is the easiest way to fuse the modalities, but the accuracy can drop in certain cases.
Typed feature structures
Introduced in 1997 by Cohen et al.4, typed feature structures consist of a collection of feature-value pairs, where the value of a feature may be an atom, a variable or another feature structure. When two feature structure are unified, a composite structure is formed, which contains the features specifications from each of the two structures.
In order to fuse two structures, some rules must be respected:
- If the values of a common feature (key) are atoms, they must be identical;
- If one of the structure value on a common feature is a variable, then the variable becomes bound to the value of the corresponding feature in the other structure (the one without the variable);
- If both the values on a common feature are variables, they become bound together;
- If both the values on a common feature are other feature structures, then the unification operation is applied recursively.
The unification process between feature structures can be represented using a Directed Acyclic Graph (DAG).
Feature structures are similar to OOP in a way, since they allow relations like is-a and is-part-of.
Each feature structure gives the information extracted by a certain modality, and by fusing them we are able to have a final decision dependent on all the fused modalities.
Melting Pots
Introduced in 1995 by Nigay and Coutaz5, melting pots are 2D structures in which the vertical axis contains the structural parts (i.e. the tasks or the objects the user interacts with) and the horizontal axis is the time (i.e. how the interaction occur sequentially or simultaneously).
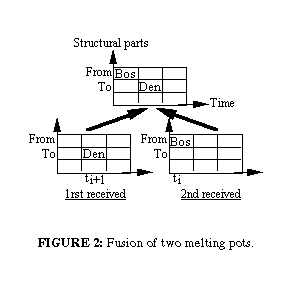 There are three different way of performing the fusion of melting pots:
There are three different way of performing the fusion of melting pots:
- Microtemporal fusion, where information that is produced either in parallel or over overlapping time interval is fused; (e.g. the user types on the keyboard while using the mouse)
- Macrotemporal fusion, that takes care of either sequential inputs or time intervals that do not overlap but belong to the same temporal window; (e.g. the user first clicks a button and then, after a pause, types a command with the keyboard. The system has to respect the timing)
- Contextual fusion, which combines the input according to contextual constraints without attention to temporal constraints. (e.g. the user interacts with two parts of an interface where the context is linked, such as selecting a menu option and then dragging an time)
Temporal windows refer to specific periods during which inputs are considered for fusion. These windows help define how the different inputs have to be grouped and processed together.
Temporal windows could be fixed intervals (like 5-second windows) or dynamic periods that start and end based on specific user actions or system states.
Macrotemporal fusion is triggered by temporal windows, since they determine which sequential inputs should be grouped together based on their timing.
Semantic Frames
Introduced by Vo and Wood in 19966, and then by Russ et al. in 20057, semantic frames are composed of slots that specify the command parameters (the action to carry out, or the object to act on) and are generated from each input modality. A frame merging algorithm then combines the frames, which may be incomplete or ambiguous, into a complete frame by selecting slots values from each frame in order to maximize a combined score.
Hybrid multi-level fusion
In hybrid multi-level fusion in which we distribute the input signals among the acquisition, recognition and decision level.
Finite-state transducers
Introduced by Johnston and Bangalore in 20008 , finite-state transducers are finite-state automatas where each transition consists of an input and an output symbol.
They can be interpreted as a tape finite state automatas, where the tapes are for the input modalities, and one tape is for the output. The automata is able to read the information from the modalities and combine them into a single interpretation.
Multimodal grammars
In multimodal grammars, the outcome of each recognizer is considered as a set of terminal symbols of a formal grammar, which can be recognized by the parser as a unique multimodal sentence. The grammar is then used to interpret the sentence.
The first grammar-based approaches, named MUMIF (Mountable Unification-based Multimodal Input Fusion), was introduced by Sun et al. in 20069. Another approach was then proposed by D’Ulizia et al. in 200710
tags: multimodal-interaction
Footnotes
-
A Framework and Toolkit for the Construction of Multimodal Learning Interfaces.pdf (page 46) ↩
-
Integration of audio-visual information for use in human-computer intelligent interaction.pdf ↩
-
Integration of Speech and Gesture for Multimodal Human-Computer Interaction.pdf ↩
-
QuickSet- Multimodal Interaction for Distributed Applications.pdf ↩
-
A Generic Platform for Addressing the Multimodal Challenge ↩
-
Building an application framework for speech and pen input integration in multimodal learning interfaces.pdf ↩
-
Semantic based information fusion in a multimodal interface.pdf ↩
-
A Novel Method for Multi-sensory Data Fusion in Multimodal Human Computer Interaction.pdf ↩
-
A Hybrid Grammar-Based Approach to Multimodal Languages Specification.pdf ↩