An RDD is an abstraction of Spark that models a collection of elements of the same type. It can be seen as a generalization of the key-value pairs used in MapReduce.
Partitions
Since RDDs can model a large amount of data, each of them is split into chunks called partitions that are distributed across the nodes of the cluster.
The programmer can specify the number of partitions for a certain RDD, otherwise Spark will choose a default number. Generally the number should be 2 or 3 times the number of cores. Programmers can also decide whether to use the default Hash Partitioner or a custom one.
Partitions are useful in order to perform task in a parallel way and in order to mantain the whole partition in the main memory, in order to not access the disk, that is an expensive operation.
Characteristics of RDDs
RDDs are immutable, and can be created from data stored on a distributed file system or as a result of transformations of other RDDs.
As said before, since RDDs operations are lazy evaluated, they don’t need to be always materialized. Each RDD maintains a “trace” of transformation, called lineage, that led to its current status. This is useful to optimize the transformations and to re-create the RDD in case of failure.
Operations
Three different kind of operations are possible on an RDD:
- Transformations: generate a new RDD from a certain RDD . A transformation can be:
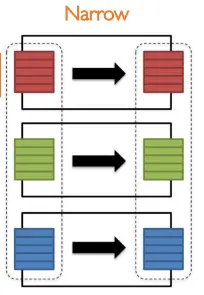
- Narrow: each partition of contributes at most to one partition of , meaning that the information in each partition of is enough to perform the transformation. An example of this is the function.
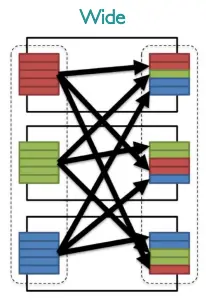
- Wide: each partition of may contribute to multiple partitions of , meaning that the information in each partition of alone may be not enough to perform the whole transformation, and so there may be the need to transfer the data across the nodes. An example of this is the operation.
- Narrow: each partition of contributes at most to one partition of , meaning that the information in each partition of is enough to perform the transformation. An example of this is the function.
- Actions: launch the computation that will apply the transformation to the RDD , this leads to the materialization of the RDD .
- Persistence: save the RDD in memory for later actions.
Spark DataFrame and Dataset APIs
Since RDDs aren’t structured, Spark provides the Dataframe and Dataset APIs, that are two APIs that allow to operate over RDDs like they are structured tables in a relational database.
Spark’s DataFrames are similar to Pandas’ DataFrame, meaning they’re a distributed collection of data organized in to named columns that allows an higher level of abstraction over the vanilla RDDs.
The Dataset API is only available on Scala and Java, and is an extension of the DataFrame API that is object oriented and type safe.
Since DataFrames are just an abstraction of RDDs, they are also immutable and lazy evaluated, and can be turned back to RDDs.