In the context of multimodal interaction, coordination is necessary when we use complementary channels (or with redundancy), meaning the information from different channels has to arrive to the user at the same time. In the case the signals are not complementary, then we don’t need coordination.
Multimodal coordination has three kinds of components:
- A modality recognizer of each modality that translates the user input according to the proper grammar.
- A module for multimodal input fusion that takes the input from the multiple recognizers and fuses the results.
- A module for fission, which accepts the fused result and provides user feedback via multimodal output.
When humans communicate with each other, the input and output modalities are typically the same. This is called input/output modality symmetry. This doesn’t always happen in human-system interaction, and so we can have an asymmetric interaction. In the most cases we input to the computer with a keyboard and mouse, and we get the output with visual or auditory information, or a combination of both.
Defined by Jakob Nielsen in 19861, the virtual protocol model is a set of levels for human-computer communication.
- Goal, which represent the real world concept, external to the computer;
- Task, which are computer-oriented objects and actions;
- Semantics, defined as the meaning of action and object within the system context.
- Syntax, which refers to the structure and rules for combining tokens into sentences or commands that the computer can understand.
- Lexical, which defines the tokens, which are the smallest units that carry information and can be recognized by the computer.
- Alphabetic: Contains lexemes, which are primitive symbols or characters that make up the tokens.
- Physical: Encompasses the input/output hardware and the physical interactions such as light, sound, and movement that occur during human-computer interaction.
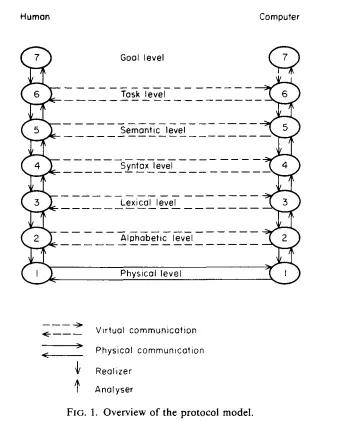 Nielsen’s virtual protocol model tells us that a communication on level of the model is realized by an exchange of information on level . This is similar on how the TCP-IP Stack stack works. (Peers virtually communicate directly, but the message is always passed to the lower level first).
Nielsen’s virtual protocol model tells us that a communication on level of the model is realized by an exchange of information on level . This is similar on how the TCP-IP Stack stack works. (Peers virtually communicate directly, but the message is always passed to the lower level first).
Differences with the Norman’s seven stages of action
The protocol seems somehow similar to [[Interaction Design#|Norman’s cycle for multimodal interaction]], the Nielsen protocol explains more the different levels of communication that the user has with the computer, from the most high level (Goals) to the most low leve (Physical). On the other hand, Norman’s stages of actions encompass more of a set of actions the user does in order to reach a particular goal, and know that that particular goal has been effectively completed, but doesn’t say anything on how the interaction between the human and the computer happens.
Time relationships and Cooperation between modalities
Timing is an essential element in multimodal systems. Different channels most of the time have a temporal relationship. In fusion, most of the time we need the temporal information on when the fusion needs to start, this because different modalities require more time with respect to others (speech require more time to be executed than gestures).
Jean-Claude Martin in 1997 classified and formally defined different kind of time relations and types of cooperation.
Note
The paper called “Towards intelligent cooperation between modalities. The example of a system enabling multimodal interaction with a map” is no longer available on the web
He also defined a modality as a process receiving a set of chunks of information and producing a chunk of information .
Time relations can be classified in sequential (one after another) and simultaneous. Note that the modalities can have an overlap where they are simultaneous only in that specific time period.
The cooperation can be classified in many types:
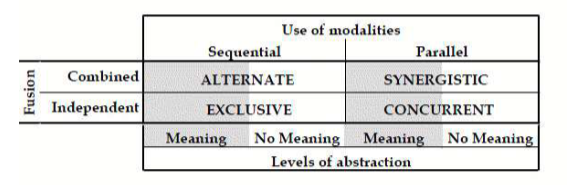
- Complementarity: different chunks of information are given by each modality, and they have to be merged, otherwise the system won’t know the entire information. The put-that-there system is an example of complementarity between modalities. Most of the time, in this type of coordination, we have a simultaneous time relationship between the modalities. Timing here is crucial, let’s consider again the put-that-there example, the system has to merge the information of both modalities where the user says there and when they point at the screen. The latter interaction is also called synergistic interaction. While a sequential interaction is when the user uses the two complementary modalities in order but without overlap (first says “put that there” and only then pointing or selecting the place);
- Concurrency: different chunks of information are given several modalities at the same time, but they are not complementary, and so they don’t have to be merged. This allows a faster interaction since the modalities are simultaneous.
- Equivalence: also known as alternative, a chunk of information can be processed as an alternative information by either of the involved modalities. This is done in order for the user to select the modality they prefer to interact with the system. An example is the voice transcription on the keyboard, where the user may decide to select it in order to input the text with their voice instead than by using the keyboard.
- Redundancy: the same information is given by the involved modalities. This is useful to avoid interpretation errors. An example of input redundancy is a user clicking the “x” on the window to close it, and at the same time uttering the word “quit”. The system won’t ask for a confirmation, since it has two modalities that say that the user wants to quit the application. An example of output redundancy is the ringtone and the vibration at the same time when a phone call arrives.
- Specialization: a special kind of information is always processed by the same modality. In particular, we can have:
- Modality-relative specialization: a particular token in a certain modality is used to convey only a type of information (e.g. a sound that always convey the “error” information)
- Data-relative specialization: if a certain event produces only a token of a certain modality (e.g. error that only produce sound and never graphics or text).
- Transfer: a chunk of information produced by a modality is used by another modality. E.g. a mouse click provokes the display of an image.
- Addition: different modalities add up different expressiveness to give more information;
- Elaboration: express partly the same information in different modalities;
- Stand-in: fail to express the same information when using another modality.
- Conflict: the two modalities cannot be handled together by the human system.
- Substitution: a modality is replaced with another modality to express the same information ( todo what changes from this and equivalence?).
Modalities can also be classified based on their design space, as we can see in the following figure:
tags: multimodal-interaction see also: