Data Preprocessing
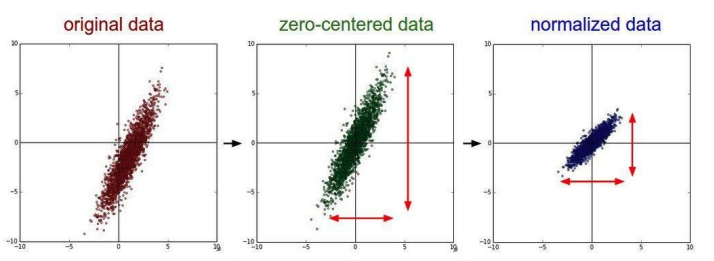 A good practice as data preprocessing is to zero-center and normalize the data.
A good practice as data preprocessing is to zero-center and normalize the data.
Zero center means to subtract from each datapoint the mean. This is useful since we will have data that will be positive and negative, and we cannot have the case in which the data is all positive or all negative.
Other techniques may be apply PCA to decorrelate data, which may help on small dataset. It’s also possible to encode PCA in the network in order for it to be able to learn it in the case it finds it useful.
Weight Initialization
The weight initialization in deep networks is a major part during training. If the weights are initialized to a small or big number, the activation function may kill the gradients.
A good initialization is the Xavier initialization.
Data Augmentation
Data Augmentation is the operation of producing new training images by applying random transformations. This allows the network to have more data to train with, and can introduce some properties, like rotation and translation invariance in the case of CNNs.
It’s a good idea to choose the transformations that match what could happen to the data in the real world.
Other Regularization Techniques
- Fractional Pooling randomizes the pooling region;
- Stochastic depth means skipping some layers in the network during training by adding residual connections, but using all layers during testing.
- Cut out is a technique in which part of the image is erased during training, and the images are left untouched at test time.
- Mixup is a technique in which you can combine signals (pictures in this case) along with the target labels. (I randomly blend the pixels of 40% cat and 60% dog, and the target will be cat: 0.4 and dog: 0.6). This is kind of strange at first glance, but it actually works very well.
- DropConnect: similar to dropout, but zeros-out the weights (connection between the neurons) instead of the neurons themselves.
Transfer Learning
Transfer Learning is the operation that allows to use knowledge learned from a task to be re-used for another task.
Since most of the very capable models need a lot of data and resources to be trained, we can train them just once on a big dataset, and then transfer the knowledge to another problem, by just fine-tuning the model with a smaller dataset.
Since the first layers of a CNN capture some general patterns that do not depend too much on the dataset, those are very generalizable, and so they can be re-used. On the other hand, the last layers capture larger and more specific patterns.
The idea is to freeze the layers that act as feature extractors, remove the classifier layers and add new fully connected layers tailored for the new problem (if the number of classes is different, the final vector should be different).
By freezing all the layers but the added ones we mean that those weights won’t be updated.
If the dataset is small we can just add the final layers, on the other hand if the dataset is quite big, it’s probably needed to unfreeze some other layers in order to fine-tune the feature extraction too.
Transfer learning works best when the dataset is very similar to the original dataset.
tags: machine-learning