todo merge it with Graph Neural Networks
How GNNs work
A GNN layer uses a separate MLP on each component of the graph. For each node vector we apply the MLP and get back a learned node-vector, this is also done for each edge and for the global-context vector (which allows to learn a single embedding for the entire graph, in order to do graph-level tasks).’
Note that the GNN layer do not update the connectivity of the graph.
Once we have done that, we have to make the prediction. We will consider the case of binary classification, but the same rules apply for multi-class classification or regression.
If the task is to make binary predictions on nodes, the graph already contains node information, and so we just apply a linear classifier for each node embedding.
If we need information about the nodes, but we can only use the information stored in the edges (like in the case of the Karate problem), than we need something else.
GNN layers can be stacked together.
Pooling
Pooling allows to collect information from edges and give them to the nodes for prediction. This works in two steps:
- For each item to be pooled, gather each of their embeddings and concatenate them into a matrix.
- Aggregate the embeddings, usually via a sum operation.
If we want to make prediction on a node, we will gather the embeddings of the connection that the node has with the others, and aggregate that embedding. We can of course also proceed in the opposite way, if we have an embedding-level task and we want to use the information inside of the node.
In the case of graph-level task, we will gather all the available information inside of a single embedding (all the nodes or all the edges).
Spatial Convolution - Passing messages between parts of the graph
Pooling can be also used within a GNN layer in order for the learned embeddings to be aware of the graph connectivity. We achieve this with using message passing, which work in three steps:
- For each node (or edge) in the graph, gather all the neighbouring node (or edge) embeddings.
- Aggregate all the embeddings (also called messages in this context) via an aggregate function like sum.
- All the pooled messages are passed trough an update function, that is usually a learned neural network.
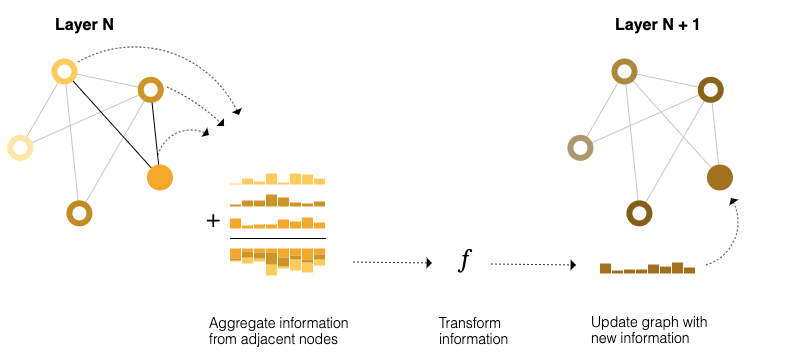 This is similar to classic convolution, and it’s used in the same way to update an element’s value by processing the information around it’s neighbourhood.
This is similar to classic convolution, and it’s used in the same way to update an element’s value by processing the information around it’s neighbourhood.
By stacking message passing GNN layer together, a node can incorporate information across further nodes in the graph. Each layer adds a step (if there are three layers, the node has information about the nodes at three steps away). Since this is not ideal for huge graphs, because a -layer architecture will propagate information at most -steps away, we can leverage the global vector, that contains information about the entire graph, as a bridge between the nodes or the edges when we are passing messages.
Since the pooling can be done only at the final layers, if we want to pass information betwen edges to nodes and viceversa, we have to aggregate their embeddings. The problem is that edges embeddings and nodes embeddings might live in different spaces. What we can do is learn a node-edge embedding linear mapping in order to map embedding in the different spaces, and be able to aggregate them.
Which graph attributes we update and in which order is a design decision when constructing a GNN. We can choose to update node embeddings before edge embeddings or the other way around.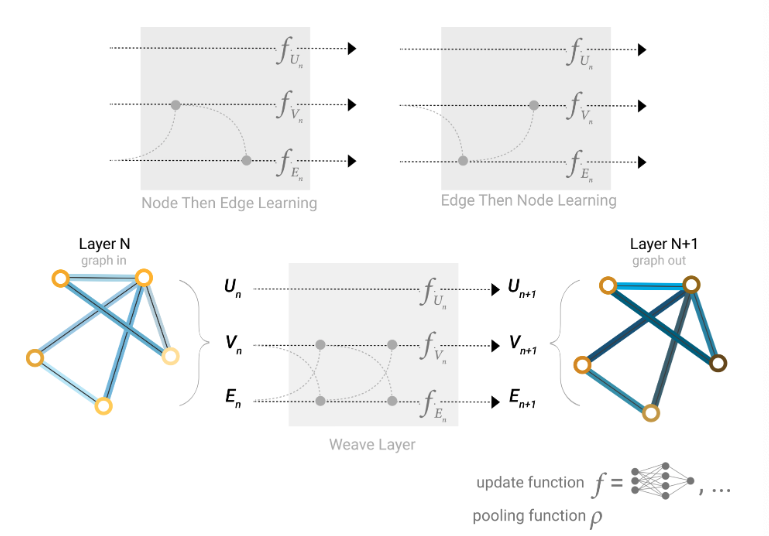 This way of passing messages is also called spatial-based graph convolution.
This way of passing messages is also called spatial-based graph convolution.
tags: deep-learning