Clustering is an unsupervised machine learning technique used to group objects in a certain number of groups (clusters), in a way that the distance between the elements within the same cluster is minimized, while the distance between elements of different clusters is maximized.
By doing so, elements within a cluster should be of the same type, meaning they are very similar.
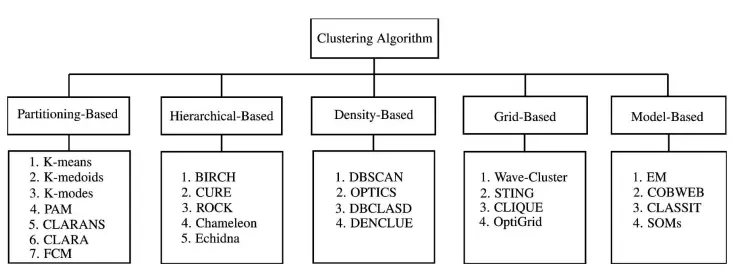
There are many categories of clustering algorithms.
 The most common partitioning-based clustering algorithm is K-Means clustering.
The most common partitioning-based clustering algorithm is K-Means clustering.
todo: maybe insert also the other algorithms
We can measure the clustering quality with these evaluation indexes:
Clustering Techniques
-
Centroid Clustering: This method involves selecting a predetermined number of clusters (for instance, two for dog and cat owners). Centroids are established, and data points are assigned to clusters based on proximity to these centroids. The process iterates through multiple rounds for optimality.
-
Density Clustering: This technique groups data points based on density, meaning points that are closely packed together are considered a single group. Points too far away from any dense cluster are often categorized as outliers.
-
Distribution Clustering: Here, the focus is on the probability of a data point belonging to a specific cluster. By calculating the likelihood that a point fits into each of the defined clusters, businesses can make more nuanced decisions regarding customer targeting.
-
Connectivity Clustering: This method begins with individual clusters and builds connections based on the similarity of characteristics (like pet types) across data points. The clustering is dynamic and based on relational proximity rather than just spatial distance.
clustering Sources: