When designing the interaction between the user and the system we will encounter a series of problems, probably even more if we’re designing a multimodal system.
In particular, we want to do Dialog Design, meaning we want to design the dialog between the user and the system. The dialog is defined as bi-directional communication between the system and the user, made of the set of signals (also noted as actions or sentences) that the user provides as input to the system, and the ones that the systems provides to the user as feedback.
Modeling a simple action at a very low level requires a lot of time, since a relatively simple action is composed of a lot of atomic actions.
In order to correctly design the interaction, we need the following models:
- Cognitive Models: the set of models that try to capture the way the user organizes the action, starting from the mental goal to the micro actions that allow a task to be completed (moving the hand to the mouse, moving the mouse to a certain spot to move the virtual cursor etc.);
- Task Models: they model the actual task. The difficult part here is the so-called stop problem: “when do we consider a task so elementary such that it cannot be split in simpler tasks?”
- Technology models: we model the actual computer in order to understand which actions can be done or not
- Sentence models: we model the grammar (formal language) in order to define the final terms of the grammar given a certain alphabet.
We also have to make a distinction between the goal and the task. The first is the final objective, while the tasks are the steps needed in order to achieve the goal.
The mental process when trying to achieve a certain goal uses a divide-et-impera approach, where tasks are divided into easier subtasks.
Usually the best approach when modeling an action is to start by the action that the user would do without the electronic system.
Note that some tasks can be optional depending on the actual state (open the program, or don't do it if the program is already opened).
Cognitive Modeling Methods
Let’s now see which are the main cognitive modeling methods that we can use to model the set of actions in order to reach a goal.
Human processor Model
The human processor model (MHP, from the acronym Model Human Processor) is a cognitive modeling method developed in early ’80s (infant times of human computer interaction) used to model what happen in the brain when a person interacts with the external world.
This can be used to estimate the complexity of a certain task without performing experiments.
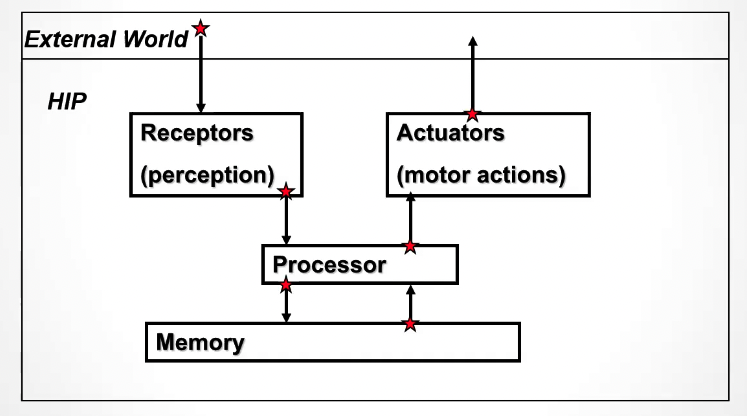
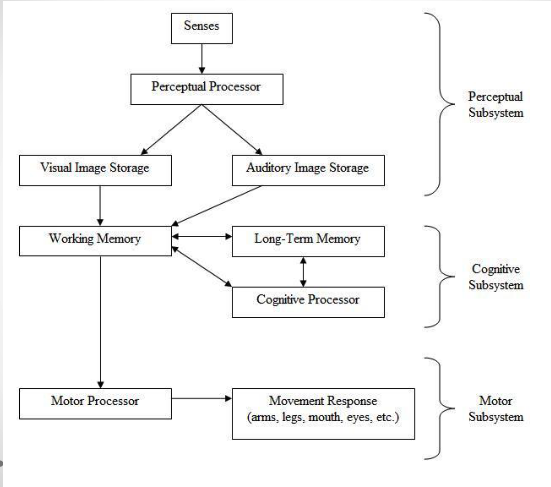 The memory is a bi-directional process since it stores new data when the user performs a task, and retrieves data in order to change the actions for certain inputs.
The memory is a bi-directional process since it stores new data when the user performs a task, and retrieves data in order to change the actions for certain inputs.
The perceptual subsystem is responsible of getting the sensory input, coding the information and outputting that into the working memory buffer, which is the memory of audio and visual images.
The cognitive processor gets the input from the working memory buffer, access the long term memory to determinate the response and outputs it into the working memory.
The motor processor gets the input from the working memory and physically actuate the response.
Norman’s seven stages of actions
The Norman’s seven stages of actions is a list of stages discusses by usability researcher Donald Normal in his book “The Design of Everyday Things”, which describes how we do a set of tasks in order to arrive a certain goal. It’s a model of how people interact with the real world.1
The list consist of these elements:
We start with a goal in mind, and so we need to do something to reach the goal. Here we define our intentions (low level statements to define what we need to do), sequence of actions and execution. In order to verify that the goal is actually achieved, we need a feedback from the real world, and so perform perception of what happened; interpretation of what happened; evaluation of what happened with respect to our goals
When designing a system, we also want to avoid:
- Gulf of execution: introduced by Norman, it’s the phenomenon when the user thinks it’s carrying on a certain set of action, but the actual execution is different, meaning the computer is doing unwanted actions. This can be caused by a badly designed user interface. (A printer icon that downloads the file instead of printing it.)
- Gulf of evaluation: again introduced by Norman, it’s the phenomenon when the feedback that the system gives to the user and its interpretation is different. For example: in our culture the red color determines a forbidden action and green a valid action. If a person of different culture interprets the colors in a different way, there is a gap between the information that the system want to output and the feedback interpretation made by the user. Also here we have a poor UI design.
Norman’s cycle for multimodal interaction
In the case of multimodal interaction, where we have multiple channels of interaction, then we need to revisit the Norman’s model as follows:
- Establishing the goal (this remains the same);
- Forming the intentions (this also remains the same);
- Specifying the multimodal action sequence in terms of human output modalities. Here each multimodal action can be specified in terms of complementary human output sensory modalities (i.e. multiple utterances at once form the action); or alternative human output sensory modalities (i.e. alternative, redundant utterances for the same actions);
- The user needs to execute each multimodal action, which can be in a sequential or synchronous manner;
- Perceiving the new system state in terms of the modalities used by the system output;
- Interpreting the system state in terms of the output modalities;
- Evaluating the systems state with respect to the initial goal. (this remain the same)
Tip
We can distinguish tasks between routine tasks and problem solving tasks. The first are carried out always the same way, and are mechanical (computing an histogram of colors of a picture); the latter instead have to be correctly designed, and their behavior changes according to the system behavior, state and other external factors.
Frameworks
Here we will discuss about HCI frameworks that deal with understanding how the user interacts with systems.
GOMS - Goals, Operators, Methods and Selection
The GOMS method is a specialized human processor model which describes the user’s cognitive structure of four components:
- Goals: what the user wants to obtain.
- Operators: atomic actions executed by the user with the purpose of changing the environment state or the user’s mental state;
- Methods: describes a procedure to accomplish the goal, by decomposing it into subgoals. A problem here where do we start (what’s the highest level task), and where do we stop (lowest level task such that it cannot be divided into subtasks anymore).
- Selection rules: a set of rules to choose among alternative methods.
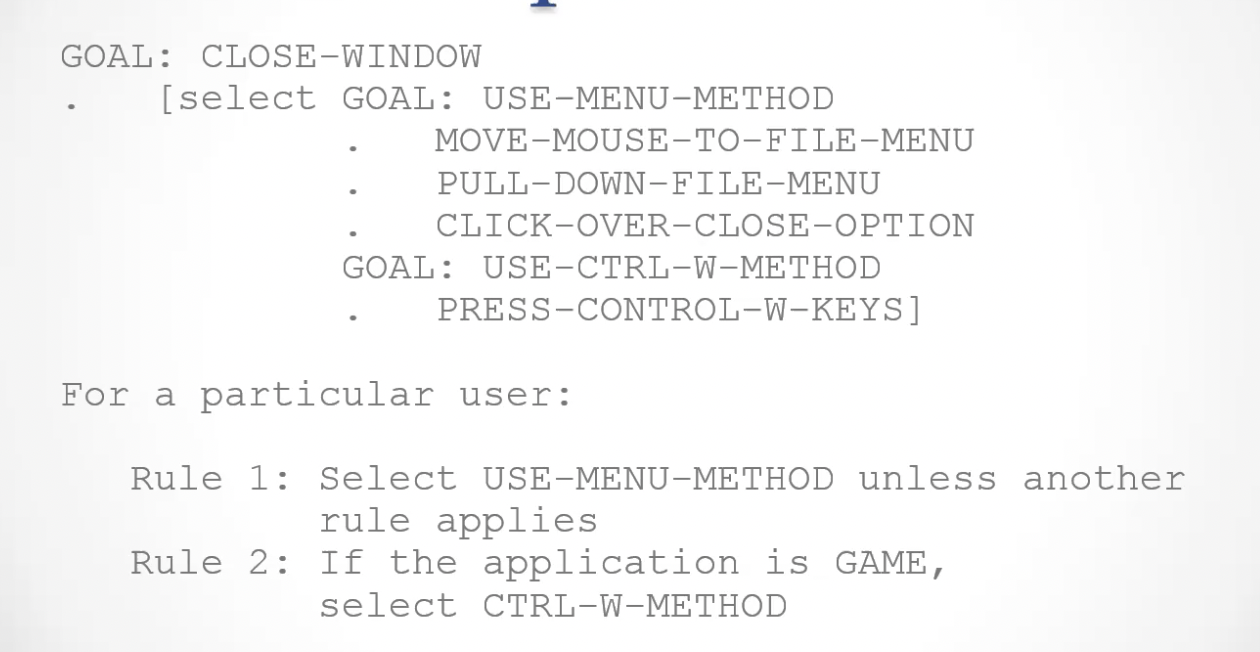 This is an example of the GOAMS method, where the original goal
This is an example of the GOAMS method, where the original goal CLOSE-WINDOWis divided into subtasks that are inside two different methods, which are selected by the selection rules at the bottom.
Modeling an actual modern system like this is pretty much impossible, but the theory is interesting nevertheless.
Action Language
Action language is a model that can be used to model some small systems, and uses a syntax very similar to the BNF (Backus-Naur Form) in formal languages.
The actions that are not embedded into the characters <> are elementary actions, that cannot be split into sub-actions.

CCT - Cognitive Complexity Theory
Proposed by Bovair and Kieras in the 1991 article The Acquisition and Performance of Text-Editing Skill A Cognitive Complexity Analysis.pdf, GOMS/CCT is an extension of the GOMS framework which is less user-centric and adds also the system’s perspective to the analysis. Furthermore, while the GOMS describes the content and structure of the procedural knowledge the user has to make the actions, the CCT introduces also the amount of knowledge (page 5).
The two main elements of the CCT model are:
- Generalized Transition Networks (GTNs), used to describe the system, and represent the system behavior and how it responds to user inputs.
- Production Rules: used to describe the users, they are similar to the GOMS methods, and describe the actions that are needed to achieve the goal. This can also be seen as a more complex version of the
if condition then action else actionstatement. The condition is something that tests the working memory (WM), while the action transforms the content of the WM.
As for GOMS’s selection rules, with many production rules I need a policy to choose one rule each time. We can define some indexes in order to estimate the complexity of the task:
- The index of learnability is defined by the number of production rules;
- The index of ease of use is defined by the number of cycles in the working memory;
- The index of transferrability is defined by the number of shared production rules for two different systems.
We can also have a parallel CCT model, meaning that multiple production rules can be executed at the same time.
An example of GOMS/CCT task when editing text with vim is the follwowing:
- We have a set of production rules
- The working memory is modeled as a set of key-value pairs:
GOAL: perform unit taskTEXT: task is insert spaceTEXT: task is at 5-23CURSOR: is at 8-7
- The rules that match with the current state of the WM are:
LOOK-TEXTtask is at%LINE%COLUMNis true, withLINE=5 COLUMN=23.
The problem with GOMS, GOMS/CCT and other hierarchical frameworks is the post-hoc technique, which is the fact that we first know how an action works, and how to accomplish it in the minimum details, and then we model it, while actually we should do the inverse first model the action and then understand how to execute it through the model).
Linguistic Notations
We can further understand the user’s behavior and cognitive difficulties by analyzing the language between the user and system. Two main notations are used in this context:
- BNF (Backus-Naur Form)
- TAG (Task-Action Grammar)
BNF - Backus-Naur Form
Used in computer science to describe the syntax of programming languages or other formal languages, it considers the dialog in a purely syntactic point of view.
The syntax is nonterminal ::= expression, where terminal terms represent the lower level of user behavior, while non-terminal determine an higher order representation of a task. An expression is a combination (expressed with +) or alternatives (expressed with |) of both terminal and non-terminal terms, that is used to define non-terminal terms.
The problems with this notation is the fact that the same syntax can define different semantics.
The second problem is that there is a low consistency control. If for examples we define two rules:
link ::= ln + filename + filename | ln + filenames + directorylink ::= ln + filename + filename | ln + directory + filenamesthe two rules are inconsistent (we can only link a filename to another filename or a set of filenames into ad directory, but not a directory to a set of filenames), but the BNF has no controls and it allows it.
TAG - Task-Action Grammar
This is similar to BNF, but it encodes the user knowledge, and parametrize the grammar rules.
Non-terminals terms are also modified to include semantics by accepting arguments, allowing consistency between different rules.
Example: We can define an operation as: Op = copy; move; link. We can then define a function that takes an operation as argument: file-op[Op] ::= command[Op] + filename + filename | command[Op] + filenames + directory. By doing this, we enforced a consistency between the three different operations.
HTA - Hierarchical Task Analysis
Introduced by Kirwan B. and Ainsworth L. in 1992^[Kirwan, B. and Ainsworth, L. (1992) A guide to task analysis], Hierarchical Task Analysis (HTA) tackles the problem of task analysis by task decomposition, which mean to divide the tasks into sub-tasks, ordering them temporally and causally.
Example: let’s say we need to clean the house, then HTA will decompose the tasks in the following sub-tasks:
- Get the vacuum cleaner out
- Fix the appropriate attachments
- Clean the rooms:
- Clean the living room
- Clean the bedrooms
- Clean the bathrooms
- Empty the vacuum cleaner
- Put the vacuum cleaner and tools away
We need to execute 1 to 5 in order, and 3.1 to 3.3 in any order. This representation of HTA has two main limitation:
- It’s not clear when an optional task (like emptying the vacuum cleaner) interrupts task before (when should I empty the vacuum?)
- It’s not clear when a series of sub-tasks that compose a bigger tasks can be done in any order (I can actually clean the rooms in any order, but here I see a precise order)
In order to remove those kinds of limitations, we can adopt a Diagrammatic description
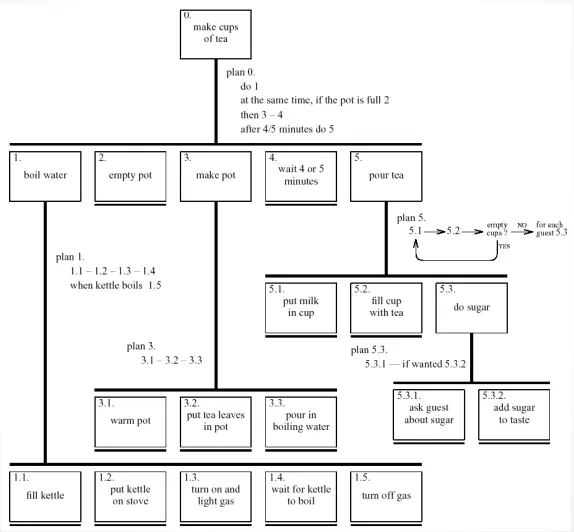
When composing an HTA diagrammatic description, we should group tasks in higher level tasks and expand only relevant tasks into lower level tasks.
The kind of plans we can use in HTA are:
- Fixed sequences:
1.1 then 1.2 then 1.3 - Optional tasks:
if the pot is full, then 2 - Event wait (it can be part of a plan if he end of the delay is an event; and part of a task if one does another task while waiting):
when kettle boils 1.4 - Cycles:
do 5.1 5.2 while there asre stille mpy cups - Concurrent tasks
do 1; at the same time... - Discretional tasks:
do any of 3.1, 3.2 or 3.3 in any order - Mix
CTT - ConcurrTaskTrees
Introduced by Fabio Paternò^[ConcurTaskTrees An Engineered Notation for Task Models.pdf], ConcurrTaskTrees are another notation for task model specification similar to HTA, but that uses a different diagrammatic notation, and makes use of the logical-temporal operators.
The different logical-temporal operators used in CTT
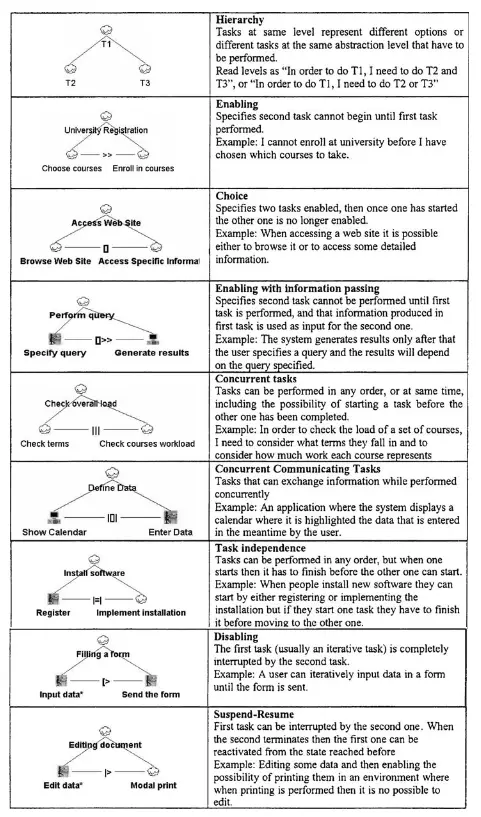
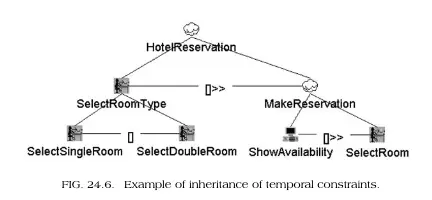
An example of a task decomposition using the logical-temporal operators.
tags: hci