Note
- Modelling is trying to ask questions
- Designing is try to give answers to those questions.
When we are modeling an application, we should separate technical skills from domain skills (and also special needs such as the one needed from impaired people).
- Technical skills are the skills that allows an individual to use certain technical tools, such as the tools to operate a patient for a surgeon, or use different input devices for a software engineer etc.
- Domain skills are the theory skills required in order to carry on the task. A physician has some domain skills, a surgeon has other ones and a software engineer still other ones.
We also need to identify the project components, and make sure to understand well the system requirements, which is not a trivial thing to do, especially when dealing with external client that don’t exactly know what they want from the system.
In a multimodal system, each channel has its own set of components and requirements, so the challenge becomes even harder.
Note
A strange challenge is also to evaluate the correspondence between the interaction tools and application logic. For example a common sense would be to use the word “procedure” to describe a patient visit, and “folder” as a collection of procedures. In an environment the people may use those terms in the opposite way, and so we need to make sure that they actually understand the meaning of the words in the application, by swapping them or by well-designing the UI. Usually we should adapt to the user way of doing things, even if they are wrong.
During the design phase, the designer should know which are the application logic components that can exploit the advantages of multimodality.
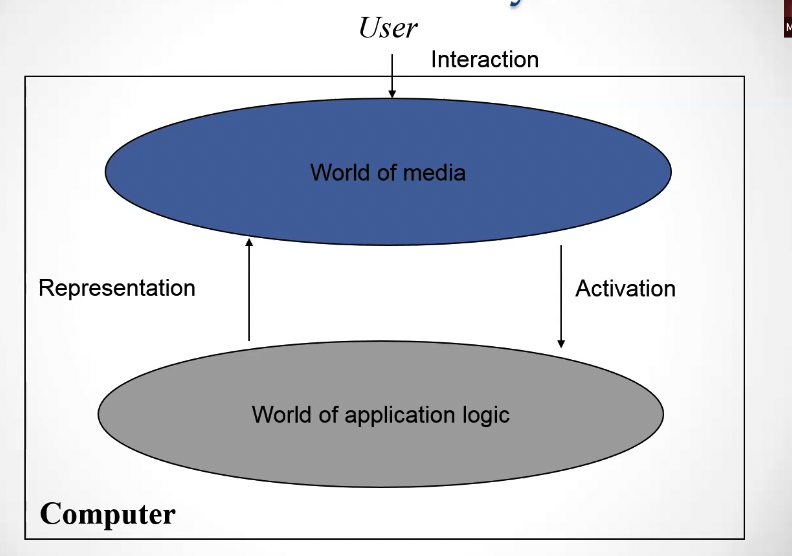
This is a schematic view of how the user interacts with the computer. The world of media is the collection of channels which the user interacts with. The world of application logic is the underlying logic that the system uses to compute results. Each time we have a translation between the two representations.
In a multimodal interaction, we have multiple instances of the world of media, since we have multiple modalities, but we have still a single application logic.
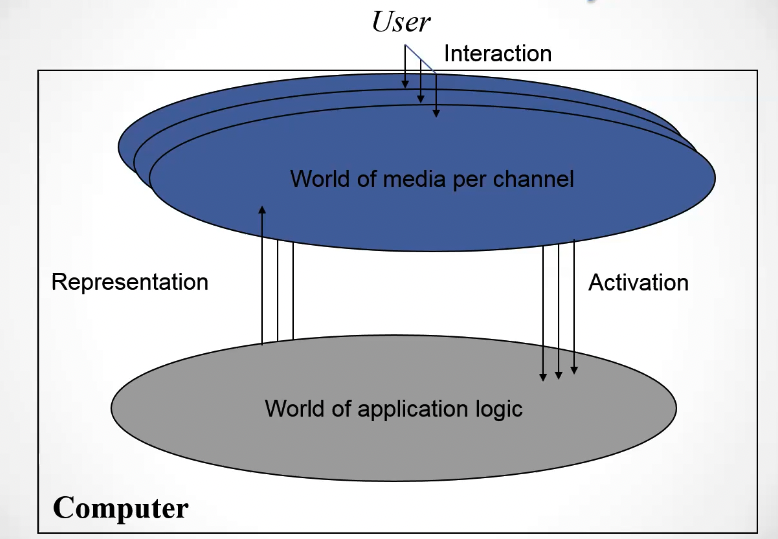
In order for the system to interpret the different modalities we need to apply fusion.
The activation process is obtained by fusing the information of different channels into a single signal, while the representation process is obtain by performing fission into different channel information.
The relation between the presentation and functionality (meaning the translation between the world of media and the application logic and vice versa) is controlled by the User Interface Management System (UIMS).
Main interactive software models
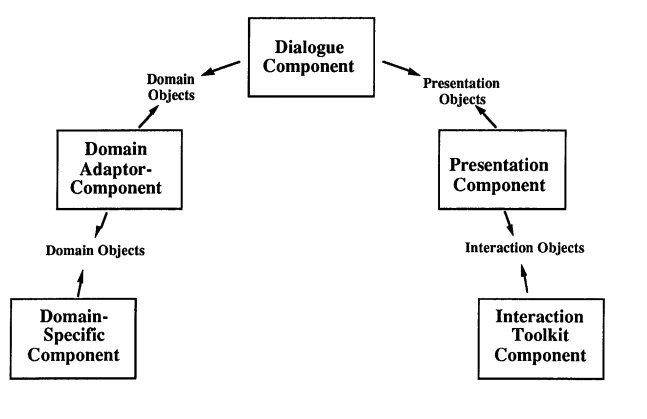
Seeheim Model
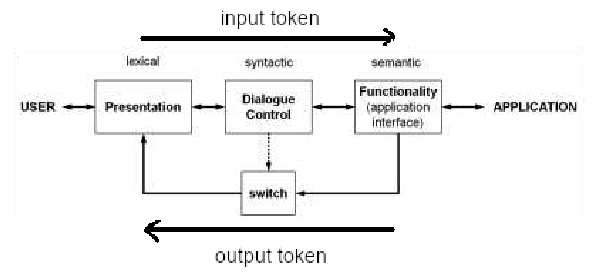
Developed in the early ’80s is the first UIMS proposed to separate the business logic and the presentation, by inserting a module called dialogue control in between, which translates the information between the presentation and the business logic using the division among lexicon, syntax and semantics:
- The lexicon in an application are the icons, or the letters in a text interface. Even the simple mouse movement is a lexicon element.
- The syntax (also called grammar) is the set of rules that determine how can we combine the different elements in the lexicon in order to create different valid concepts.
- The semantics is the meaning of each element (meaning of a word, or an icon).
The limits of this UIMS is the fact that the dialog control is monolithic, this means that when we change the presentation component (the UI), then the dialog must be rewritten to adapt it to its features. This heavy coupling is not ideal.
The other limit is that the the dialogue control makes formal description difficult.
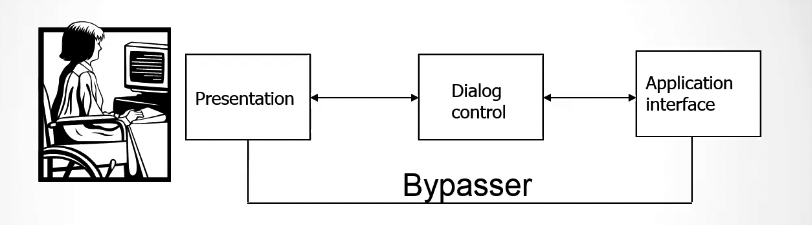
 While this is a scheme of the entire Seeheim model.
While this is a scheme of the entire Seeheim model.
The bypasser is a module that allow the application component to bypass the dialogue control for performance reasons 1.
Arch/Slinky Model
This is a modification of the Seeheim model in which more modules between the logic and the presentation are added.
As in a slinky spring, different layers may be larger, and so more important, than others in different systems and different components.
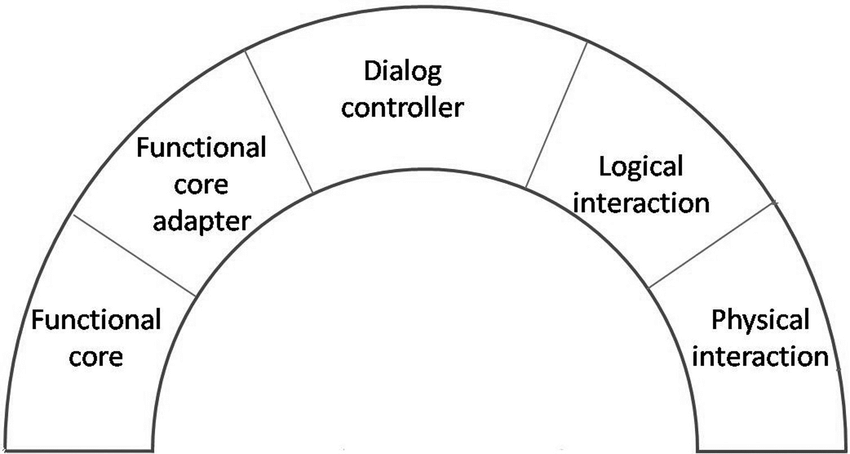
 These are two (alternative) diagrams for the arch/slinky model. More information about the model can be found in the original paper 2
These are two (alternative) diagrams for the arch/slinky model. More information about the model can be found in the original paper 2
Model View Controller
The MVC is the most modern model that tries to better separate the presentation (view) from the application logic (model) from the user input (controller).
Each module will only parse the signals that belongs to it and then pass it to another module, in order to have a very loosely coupled system.
Problems in the definition of an interactive system
When we are defining an interactive system, there are some problems regarding:
- How to define the needed components for the channels
- How to design the coordination and the reaction to the user actions and state change
- How to design the layout. Let’s see how we can solve these problems.
Defining the needed components
Regarding how to define the kind of needed components, we have to consider:
- The domain representation, meaning the data to represent and the processes to activate;
- The interaction management, meaning the generic interaction elements, the navigation elements and the support of specific behaviors.
The behaviors that a system should support are:
- Process activation;
- Information retrieval (output);
- Information feeding (input)
Coordination
Coordination policies regulate how different channels should coordinate. In particular, they need to enable or disable a certain channel; decide how the activation is propagated and what happens if the two channel are activated concurrently.
We can have a problem of coordination if the information given through a certain doesn’t arrive after a certain amount of time, and it’s essential for another channel.
An example of a coordination problem is: if I need to make a swipe gesture with my hand to the right or to the left in order to say if I want to go backwards or forwards in a page of a ebook, and then with my voice I also say how many pages I want to skip in that direction, what happens if i say the number of pages but I don’t make the gesture? This has to be handled.
todo divide the coordination in “for behavior” and “for representation”.
We also have to check the coordination that regards the user interface. For example we must have the “mutual constraints between elements”. If for example I am using a speech-to-text function, and while I speak the spoken text is being shown to me, that visual element shouldn’t interfere with any other visual element on the screen that is competing for the same cognitive resources.
More Info
For more about coordination, see Multimodal Coordination. Regarding how to proper design the layout of the system, refer to Interaction Design.
tags: multimodal-interaction resources: