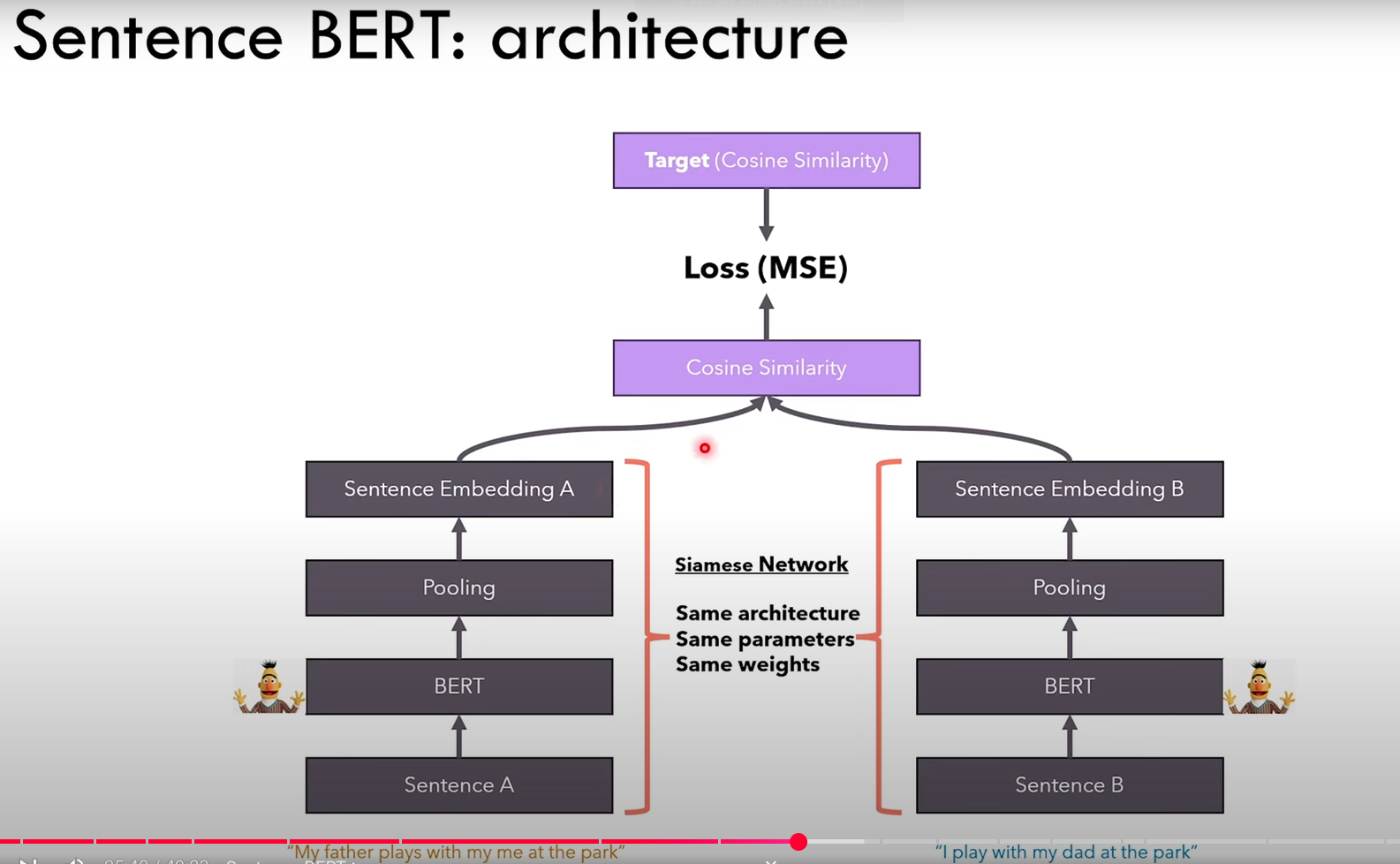
Sentence-BERT is a Siamese Network architecture composed of two identical BERT models that share weights. It is specifically trained to produce high-quality sentence embeddings. During training, it takes in pairs of sequences and optimizes their embeddings so that similar sequences have a high cosine similarity, while dissimilar sequences have a low cosine similarity. This training objective enables Sentence-BERT to generate sentence embeddings that can be meaningfully compared using similarity functions like cosine similarity, making it highly effective for tasks such as semantic search, clustering, and paraphrase identification.
Important
Since its a siamese network, even if in the diagram two models are shown, there is actually only one model. First we pass the sentence A and compute the embedding A, then we pass to the same model the sentence B and compute the embedding B.