Speech Interaction is a way of exploiting speech recognition to interact with a system using the voice. Along with Gesture interaction, speech interaction is one of the most natural way of interacting with a system.
Speech recognition means to transform a pronunciated sound to a set of characters that make up a set of words by means of an algorithm implemented as a computer program. It’s also known as speech-to-text.
The inverse of speech-to-text is text-to-speech and it's also known as Speech Synthesis)
Utterance
An utterance is defined as any sound sequence between two periods of silence, and it’s the element that has to be recognized by the speech recognition system.
Remember that the silence between two elements is essential in order to distinguish them an being able to tokenize them as different tokens.
Before Neural Networks, when the systems were less accurate, the silence between two utterances had to be marked a lot by the user, by speaking in a slower and more clear way to the machine. Nowadays with modern systems this is not longer necessary.
Utterance recognition is not a trivial task, since if the user is speaking a phrase and it makes a too long of a pause in the between, the phrase can be wrongly split into two different utterances. On the other hand, if the threshold of silence is set too low, two different phrases can be wrongly recognized as a single utterance.
What's the difference between video and speech classification? In video I can use single frames independently, while in speech a frame doesn't have a meaning.
Pronunciation
The pronunciation of a word, defined as what the word should sound like, is an essential part in a speech recognition system since it’s needed in order to successfully recognize the word. Note that each word can have multiple pronunciations.
Here we can distinguish between text-dependent and text-independent systems:
- In a text-dependent system, the system will recognize only a predefined set of sentences, which act like a set of possible commands to give. This was the case for the early speech interaction systems.
- In a text-independent system, the system will be able to recognize any type of sentence said by the user.
We can also divide a system as speaker-dependent and speaker-independent.
- In a speaker-dependent system, the system is fine-tuned on the speaker voice, meaning it will have an higher accuracy on that particular voice and pronunciation.
- In a speaker-independent system, the system is not fine-tuned on any particular voice, and the training integrates different types of voices and pronunciation of utterances. Nowadays most of the modern systems are speaker independent.
Grammars
A grammar is defined as the set of possible recognizable words and how they can connect to articulate sentences. The recognizable words are the syntax, while the semantic is the set of rules that define how to combine words together.
When dealing with speech recognition systems, the system will compare the current utterance against all the words and phrases in the active grammars and choose the one that better fits. Usually if the user says something that is not defined in the grammar, then the system won’t be able to recognize it.
As for other grammars, in the speech recognition the elements (acoustic signal in this case) are examined and structure into a hierarchy, in this context noted as: phonemes (subword units, equivalent of graphemes in NLP), words, sentences.
VoiceXML is a digital document standard for specifying interactive dialogues between a human and a computer. It’s composed of a VoiceXML browser (which is the dialogue interpreter) and a set of VoiceXML documents. The browser includes the speech recognition component, the speech synthesis, audio interfaces and dialogue manager. Each document defines a part of the dialogue flow, and consists in a finite state machine with dialogues and transitions to other documents.
<vxml version="2.0" xmlns="http://www.w3.org/2001/vxml">
<form>
<block>
<prompt>
Hello world!
</prompt>
</block>
</form>
</vxml>This is an example of a VoiceXML document.
Evaluation
When we evaluate a system one of the most important metrics is the accuracy. In the context of speech interaction, the accuracy refers to wether the desired end result occurred, while in speech recognition refers to wether. the engine recognized the utterance exactly as spoken. The value is expressed as a percentage of number of correctly recognized utterances out of the total numbers of utterances spoken.
Multiple factors in a speech recognition system can degrade the accuracy of the system, here we will explore some of them:
- Vocabulary size and confusability: the error rate increases as the vocabulary of possible words increases. The system performances can be poor even on a small vocabulary if it contains many confusable words, meaning words that have a similar pronunciation;
- Speaker dependence (as we talked before)
- Isolated, discontinuous or continuous speech: isolated speech (meaning speech where there are only single words) and discontinuous speech (words in which the silence between is very marked out) is much easier to recognize than continuous speech (naturally spoken sentences).
- Grammar perplexity: grammars are usually rated by perplexity, which is a number that represents the average number of words that can follow any given word (i.e. the branching factor). Grammars with higher perplexity are more difficult to recognize.
- Read vs spontaneous speech: spontaneous speech is harder to recognize than read speech, since it tends to be full of filler words, false starts, stuttering, incomplete sentences, coughing and laughter.
- Adverse conditions: environmental noise, low-quality equipment, limited frequency bandwidth, altering speech (shouting, then speaking quickly, then speaking slowly etc.) are other factors that may affect the system accuracy.
Methods for Speech Recognition
As said before, the task of a speech recognition system is to map phonemes to graphemes, and all the methods are based on a statistical pattern recognition task where the spoken phoneme that is the most similar to a vocabulary phoneme is selected, and then mapped into the corresponding grapheme.
todo: this is probably a general framework and not an actual method, so change it accordingly The standard approach to speech recognition assumes a simple probabilistic model.
A word sequence produces an acoustic sequence with probability . The goal is to decode the string based on the acoustic sequence such that has the maximum a posteriori (MAP) probability. Given an observed acoustic sequence , the goal is to find
Using Bayes rule, we can write: . Since is independent of , the goal is to find .
is called the Acoustic Model, since it estimates the probability of an acoustic sequence given a certain word string. The value can be computed by:
- Build statistical models from the phonemes.
- Build word models from these phonemes models, using a lexicon to describe the composition of words.
- Postulate word sequences
- Evaluate the acoustic model probabilities via standard concatenation methods.
On the other hand, is called the Language Model, since it describes the probability of having the particular sentence .
Acoustic Phonetic Approach
In this approach we assume that there exist finite and distinctive phonemes in the spoken language, and that these units can be characterized by a set of acoustic properties. The problem with phonemes is the fact that they’re highly variable, meaning that their acoustic properties can change accordingly to a set of factors, for example the speaker and the neighboring sounds (i.e. a phoneme changes pronunciation based on the neighboring phonemes, this is called co-articulation effect.). These factors are hard to include into the training process.
The approach follows these steps:
- We perform spectral analysis by using Short-Time Fourier Transform, Wavelet Transform or MFCC - Mel-Frequency Cepstrum Coefficients, to extract time-frequency features.
- We create phoneme lattices, i.e. acoustic regions in which each one has one or more phonetic labels (more phonetic labels since the phoneme may be produced by different words).
- Using linguistic constraints such as the grammar, we determine a valid word for each phoneme lattice.
We never input the model the raw speech signal, but we first extract some features, this is valid regardless the used approach. The most widely used feature vectors are Cepstral Coefficients. The word cepstral is an anagram of spectral and was created exactly for speech feature extraction.
Pattern Recognition Approach
The pattern recognition approach consists of two steps:
- Pattern training, in which we train the model to learn some speech patterns. Its representation can be done with a speech template (a feature vector that is prototype of a speech template); statistical model (like Hidden Markov Model); Dynamic Time Warping or Vector Quantization.
- Pattern comparison, in which different patterns are compared with the learned one using a distance measure and a decision threshold. Note that a pattern can be related to a single character, a word or a sentence.
When dealing with pattern recognition, different models can be used to achieve the final goal.
Template-Based Approach
In the template based approach, we store a collection of prototypical speech patterns, which are just feature vectors.
Given a new phoneme, we extract the feature vector and compare it with all the stored templates using a certain distance measure, and we match it with the template according to a certain distance threshold.
The obvious con of this approach is the fact that if the vocabulary size increases, the template computation and storage becomes very computationally expensive.
Statistical or Stochastic Model
The main difference between the template-based approach and the stochastic approach is the fact that while in the first either we match a template or we don’t, in the latter we can also take decisions if we have incomplete or uncertain information. This comes useful to attack problems like confusable words, speaker variability, environmental noise and others.
On of the most popular stochastic approaches is based on the Hidden Markov Model (HMM). This particular model allows to model the conditional probability of a certain output (a spectral vector in our case) given the pronunciated phoneme.
The hidden states are what the user has pronunciated (since the words that the person speaks are not knows), while the visible state (the observed phenomenon) are composed of spectral vector. The edges of the HMM are the conditional probabilities.
todo this part can be heavily revisited and detailed
Dynamic Time Warping
Dynamic Time Warping
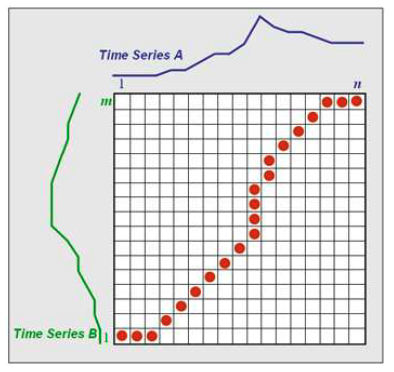
Dynamic time warping is an algorithm that aims to measure similarity between two sequences which may vary in time or speed. DWT can be applied on both audio and video.
The sequence are warped non-linearly in the time-dimension, which determines a measure of their similarity independently of the non-linear variations in the time dimension. The algorithm uses dynamic programming, and does the following operations:
- the two sequences A and B to match are arranged on the sides of a grid.
- inside each cell a distance measure can be placed, which compares the corresponding elements of the two sequences.
- the best match (or alignment) between those two sequences is given by a path on the grid.
- to find the best path, we need to find all the possible routes through the grid and for each of them compute the overall distance between A and B (computed as the sum of distances between the individual elements on the grid). We can use dynamic programming to keep track of the cost of the best path at each point in the grid.
todo can be revisited
Link to original
Vector Quantization
Vector Quantization is a technique that is used to divide continuous spaces into discrete bins in order to reduce the data dimensionality.
This can be applied to colors, which spectrum includes million of colors, but not all are needed since they cannot be even perceived by the human eye.
It works by creating different groups which are represented by their centroid point (as in k-means and other clustering algorithms). From here we have a codebook as a reference model and a codebook searcher in place of more costly evaluation methods.
This is not a method for speech recognition itself, but can be used as an intermediary step after the feature extraction and before another pattern recognition approach in order to have less vectors to deal with, reducing the complexity.
Note
Vector quantization is also used in other approaches, such as source separation, for more see: Latent Autoregressive Source Separation.pdf
Artificial Intelligence Approach
In the AI approach, we take ideas both the acoustic phonetic and pattern recognition methods, and we use machine learning or deep learning to create more sophisticated models.
Knowledge-based Approach
In the knowledge-based approach uses the information regarding the linguistic, phonetic and spectrograms. Because of this, an engineer expert in the domain is needed in order to incorporate rules and procedures inside of the algorithm.
Algorithms enable us to solve problems, knowledge enable the algorithms to work better
Neural Networks Approach
The neural network approach mitigate the problem of extracting the correct and meaningful features, since this most of the time is done automatically by the network. The new problem they rise is the interpretability, meaning finding why the model has extracted those particular features, and why did it make a particular decision as a final result. Multi Layer Perceptron, Convolutional Neural Networks and Long Short Term Memory (LSTMs) are just some example of neural networks architecture that can be used in order to perform speech recognition.
Support Vector Machine Approach
Support Vector Machines can be used to do classification. They can only classify fixed length data vectors, which is a limitation.
Feature Extraction
The main goal of the feature extraction step is to compute a sequence of feature vectors which provide a compact representation of the given input signal.
When working with audio, Fourier Transform, Short-Time Fourier Transforms and Wavelet Transform can be applied to extract the features, but usually MFCC - Mel-Frequency Cepstrum Coefficients, which is made exactly for audio, gives better results.
tags: multimodal-interaction